サイバーセキュリティにおける人工知能と機械学習
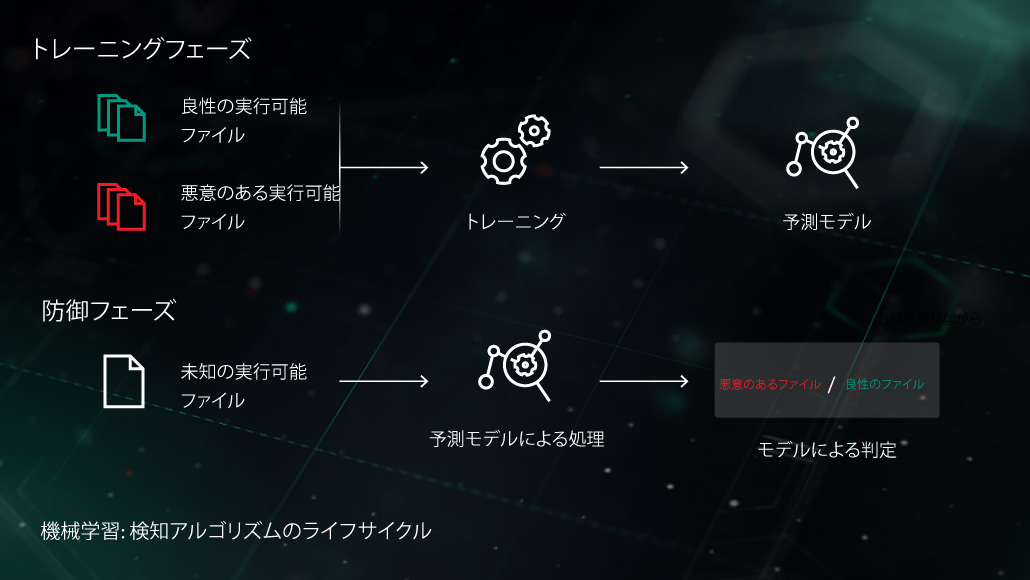
人工知能のパイオニアであるアーサー・サミュエル氏(Arthur Samuel)は、AIを「明示的にプログラムされることなくコンピューターに学習能力を与える」一連の手法と技術と表現しました。マルウェア対策のための教師あり学習の特定のケースでは、タスクは次のように定式化できます:オブジェクトの特徴の集合 \( X \)と、それに対応するオブジェクトのラベル \( Y \) を⼊⼒として与えられた場合、未確認のテストオブジェクト \( X' \)に対して、正しいラベル \( Y \) を生成するモデルを作成します。 \( X \) はファイルの内容や動作を表す特徴(ファイルの統計、使用するAPI関数のリストなど)の一部であり、ラベル \( Y \)は単純に「マルウェア」または「非マルウェア」となります(より複雑なケースでは、ウイルス、 トロイの木馬、アドウェアなどの詳細な分類となる場合があります)。教師なし学習は、データの隠れた構造を明らかにすることを目的とします。たとえば、類似するオブジェクトや相関性の高い特徴のグループを探します。
Kasperskyの次世代型の多層的な防御は、機械学習などのAI手法を検知パイプラインのあらゆる段階で幅広く使用しています。受信ファイルストリームの前処理に使用する拡張性に優れたクラスタリング手法から、ユーザーのマシン上で直接動作するふるまい検知を可能にする、強固でコンパクトなディープニューラルネットワークモデルまで、その手法は多岐にわたります。これらの技術は、非常に低い誤検知率、モデルの解釈可能性、敵対的行為への耐性など、実世界のサイバーセキュリティ製品のいくつかの重要な要件に対応するように設計されています。
機械学習ベースの技術のうち、Kasperskyのエンドポイント製品で使用されている重要なものをいくつか検証してみましょう:
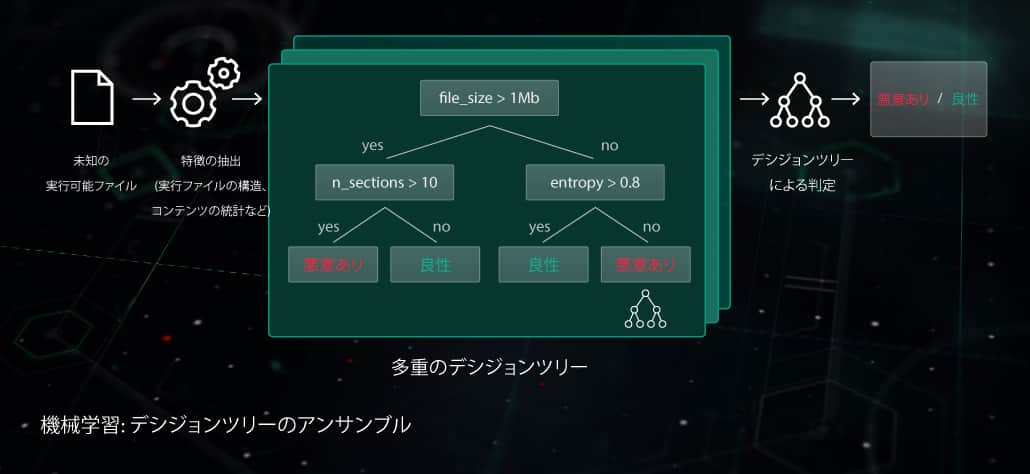
決定木アンサンブル
このアプローチでは、予測モデルは決定木(ランダムフォレストや勾配ブースティング木など)の集合の形をとります。ツリーのすべての非リーフノードにはファイルの特徴に関する質問が含まれ、リーフノードにはオブジェクトに関するツリーの最終決定が含まれます。テストフェーズでは、モデルは検討対象のオブジェクトの対応する特徴を持つノードの質問に回答しつつ、ツリーを走査します。最終段階で、複数のツリーの判定がアルゴリズム固有の方法で平均化され、オブジェクトに関する最終的な決定が下されます。
このモデルは、エンドポイント側でプロアクティブな保護を実行する前の段階においてメリットがあります。この技術を適用した当社のコンポーネントの1つとして、モバイル脅威の検知に使用されるCloud ML for Androidがあります。
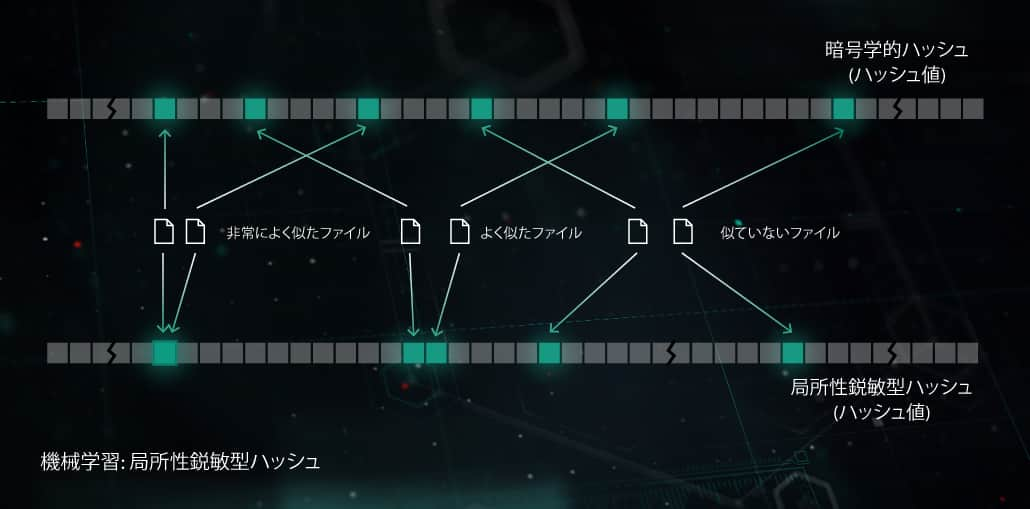
類似性ハッシュ(局所性鋭敏型ハッシュ)
以前は、マルウェアの「フットプリント」を作成するために使用するハッシュは、ファイルのどんな小さな変更にも敏感に反応していました。この欠点は、サーバー側のポリモーフィズムなどの難読化手法を使用してマルウェア作成者によって悪用されていました:マルウェアを少し変更するだけで、検知をすり抜けることができたのです。類似性ハッシュ(または局所性鋭敏型ハッシュ)はAI手法の1つであり、類似した悪意のあるファイルを検知します。検知する際、システムはファイルの特徴を抽出し、直交射影学習を使用して、最も重要な特徴を選択します。その後、機械学習ベースの圧縮が適用され、類似した特徴の値ベクトルが類似または同一のパターンに変換されます。この手法は汎化能力に優れており、検知レコードベースのサイズを大幅に削減します。なぜなら、1件のレコードでポリモーフィック型マルウェアのファミリー全体を検知できるからです。
このモデルは、エンドポイント側でプロアクティブな保護を実行する前の段階においてメリットがあります。また、Kasperskyの類似性ハッシュ検知システムに適用されています。
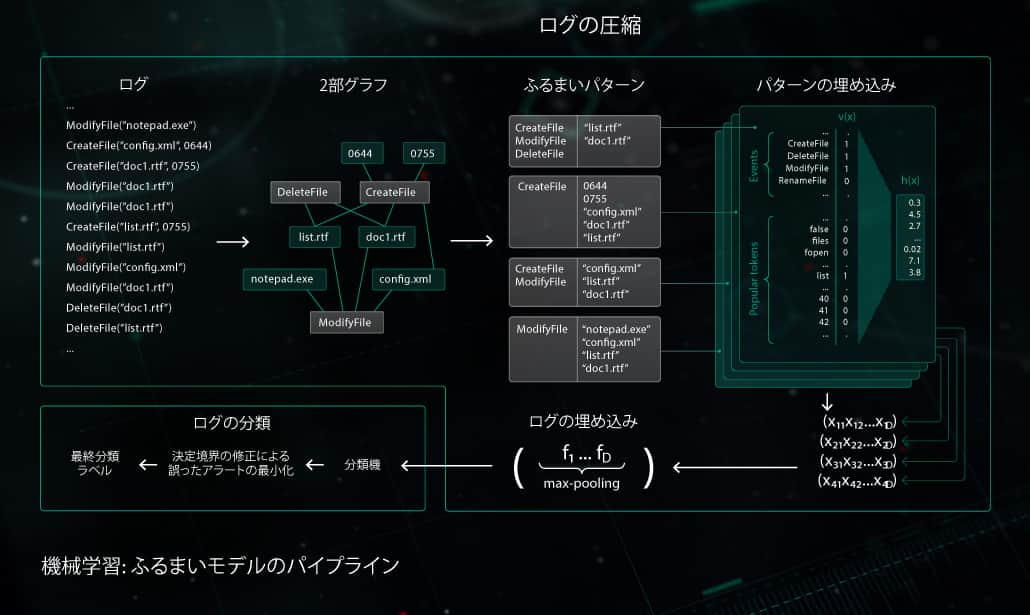
ふるまいモデル
監視コンポーネントは、ふるまいログを提供します。ログには、プロセス実行中に発生したシステムイベントのシーケンスと、対応する引数が含まれています。観測されたログデータ内の悪意のある活動を検知する目的で、当社のモデルは取得した一連のイベントをバイナリベクトルに圧縮し、クリーンなログと悪意のあるログを区別できるようにディープニューラルネットワークをトレーニングします。
ふるまいモデルを使用したオブジェクト分類は、エンドポイント側のKaspersky製品の静的検知モジュールと動的検知モジュールの両方で使用されます。
AIは、ラボにおけるマルウェア処理の適切なインフラを構築する上でも、同様に重要な役割を果たします。Kasperskyが目的としているインフラ構築には、次のようなものがあります:
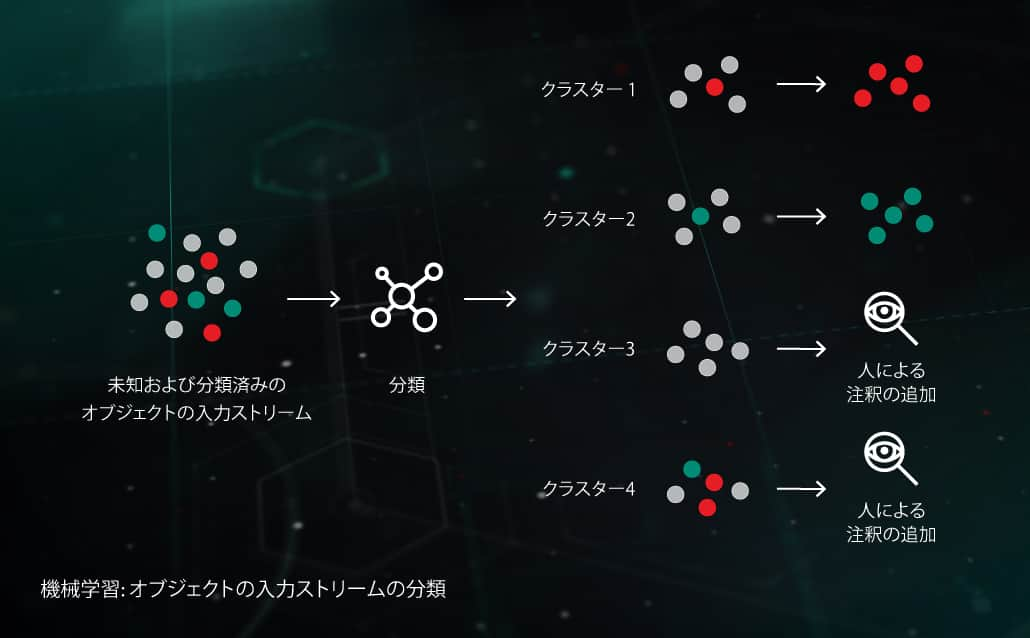
受信ストリームのクラスタリング
機械学習ベースのクラスタリングアルゴリズムにより、当社のインフラに大量に送られてくる未知のファイルを、適切な数のクラスタに効率的に分類することができます。その一部は、その中に存在する既にアノテーションが付けられたオブジェクトに基づいて、自動的に処理することができます。
大規模な分類モデル
特に強力な分類モデルの一部(巨大なランダム決定フォレストなど)は、コストが高い特徴抽出機能とともに、膨大なリソース(プロセッサ時間、メモリ)を必要とします(たとえば、詳細なふるまいログを取得するためにサンドボックス経由での処理が必要になる場合があります)。したがって、モデルをラボで保有して実行し、その後、大規模なモデルの出力決定に基づいて軽量な分類モデルをトレーニングすることで、これらのモデルから得られた知識を抽出するアプローチの方がより効果的です。
AIの機械学習の側面を使用する際のセキュリティ
MLアルゴリズムは、研究室という限定された環境から現実世界へと解放されると、AIシステムにエラーを意図的に発生させることを目的とした各種の攻撃に対して脆弱になる可能性があります。こうした攻撃により、トレーニング用データセットを有害なものに置き換えられたり、モデルのコードがリバースエンジニアリングされたりする可能性があります。さらに、ハッカーは専用に開発された「敵対的AI」システムを利用して、機械学習モデルを「総当たり攻撃」する可能性もあります。このシステムは、自動的に多数の攻撃サンプルを生成し、モデルの弱点が発見されるまで、保護ソリューションや抽出された機械学習モデルに対して攻撃を仕掛け続けることができます。AIを使用するマルウェア対策システムがこのような攻撃を阻止できない場合、その影響による被害は壊滅的なものになる可能性があります:トロイの木馬の特定を誤っただけで、何百万ものデバイスが感染し、莫大な経済的損失がもたらされる結果になります。
このため、セキュリティシステムにAIを使用する場合には、以下の重要事項を考慮する必要があります:
- セキュリティベンダーは、敵対者が存在する可能性がある現実世界において、AI要素のパフォーマンスに関する必須要件(想定される敵対的行為への耐性など)を理解し、細心の注意を払ってその要件の充足に尽力する必要があります。機械学習やAIに特化したセキュリティ監査や「レッドチーム演習」は、AIの側面を使用するセキュリティシステムの開発における重要な要素となるはずです。
- AIの要素を使用するソリューションのセキュリティを評価する場合は、そのソリューションがサードパーティのデータやアーキテクチャにどの程度依存しているかを確認しましょう。多くの攻撃は、サードパーティの入力データ(脅威インテリジェンスフィード、公開データセット、事前トレーニングされた外部委託のAIモデルなど)に基づいているためです。
- 機械学習やAIの手法を、万能な解決策として位置づけるべきではありません。あくまで多層的なセキュリティアプローチの一部として、補完的な保護技術や人間の専門知識と互いに連携し、双方の弱点をカバーし合う形で機能する必要があります。
Kasperskyは、機械学習やそのディープラーニングのサブセットなどのAIの側面をサイバーセキュリティソリューションで効率的に使用するという点において豊富な経験を有していますが、これらの技術は真のAI、すなわち汎用人工知能(AGI)ではないことを認識することが重要です。機械が完全に自立して、ほとんどの作業を完全に自律的に行うことができるようになるまでには、まだ長い年月を要します。それまでは、サイバーセキュリティにおけるAIのほぼすべての側面で、人間のエキスパートの指導と専門知識が必要になります。これにより、システムの高度化と精緻化が推進され、時間はかかりますがその能力が徐々に向上していきます。
機械学習およびAIのアルゴリズムに対する一般的な攻撃やその防御方法に関する詳細な概要は、当社のホワイトペーパー「AI under Attack: How to Secure Artificial Intelligence in Security Systems」を参照してください。

